データソースとしてのウェブ
どのようにすればもっとインターネット上にしか存在しない情報を見つけてくることが出来るのだろうか? 本章ではあなたがメールアドレスやウェブサイト、あるいは画像やウィキペディアの記事など、様々なものを調べる時、それらの調査対象の素性に関する情報を教えてくれるいろいろなツールを紹介する。
ウェブツール
はじめに特定のページについてよりもサイト全体の詳細を発見するために使うことができるいくつかのサービスだ:
- Whois
-
どんなウェブサイトについても基本的な登録情報が得られるのが whois.domaintools.com だ(またはMacのTerminal.app で「whois ウェブサイト名」 と打ち込む)。最近はプライベート登録を選択することで詳細情報を隠蔽しているサイトオーナーもあるが、多くの場合はサイトを登録したオーナーの名前、住所、eメールアドレス、電話番号がわかる。IPアドレスを打ち込んだ場合、そのサーバーを所有する組織または個人についてのデータが得られる。これはサービスを悪用したり不正使用するユーザーについて、もっと詳しく情報を得たいときに便利である。多くのウェブサイトは利用者のIPアドレスを記録しているものだからだ。
- Blekko
-
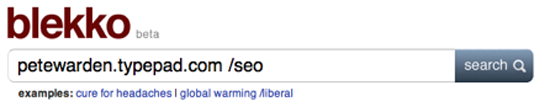
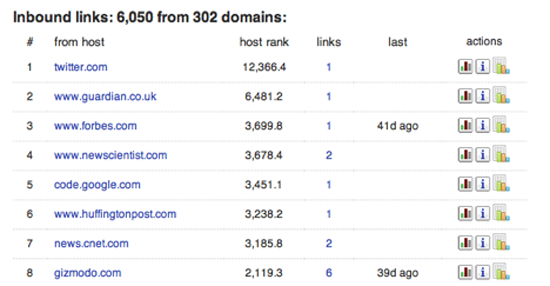
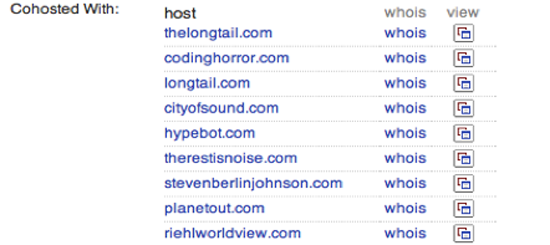
Blekko search engine は、ウェブをクロールして内部的にさまざまなサイトの統計を取り、その膨大な知見を提供する。ドメイン名に続けて "/seo"と入力することで、そのURLについて1ページにまとまった情報が得られる。(訳注: blekko.comは2015年にIBMに買収されている。) Figure 7 に示した最初のタブは、そのドメインにリンクする外部のサイトを人気順に示すものである。これはそのサイトがどのような人たちに読まれているか理解するのにきわめて便利である。また、Googleでの検索ランクはこうした外部からのリンクに基づいているので、なぜそのサイトが高いランクを持っているか知りたい時にも便利だ。Figure 8 は同じマシン上にある他のウェブサイトを示している。スキャマー(詐欺師)やスパマーは互いにレビューしリンクし合う複数のサイトを作ることで正当性を偽造するのが普通である。一見するとそれぞれ独立のドメインに見えるし、登録情報の詳細まで違っていることもあるが、実際のところ、コストが圧倒的に安く済むため、同じサーバーに同居させている場合が多い。こうした統計情報を利用することで、調べているサイトの隠れたビジネスのカラクリを解明することができる。
- Compete.com
-
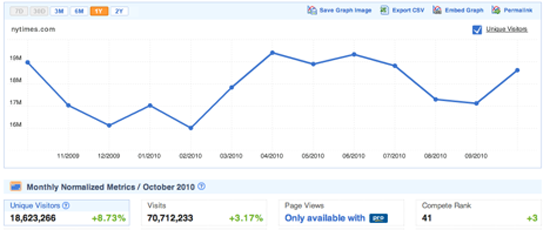
compete.com はアメリカの消費者を横断的に調査する手法によって多くのウェブサイトの詳細な利用統計を構築し、ごく基本的な情報については無料で提供している。Site Profileタブを選んでドメイン名を入力してみよう(Figure 9)。そのサイトの過去一年間のトラフィックのグラフと、ビジター数、その頻度の数字が表示される(Figure 10)。調査データを元にしているので数字は概数となっているが、筆者が内部の数字と比較したところ、わりに正確なものであった。ふたつのサイトを比較するときの情報源としては特に有用で、これは厳密な数字はどちらについても取れないものの、人気度の相対的な差はよく示してくれるためだ。合衆国内の消費者についてのみの調査なので、国際的によく利用されるサイトについてはデータの品質は悪い。
- Google’s Site Search
-
あるドメインについてすべてのコンテンツを調べたいときに非常に便利なのが"site:"キーワードである。検索語に"site:example.com"を追加すると、Googleはこの指定されたサイト(example.com)の結果だけを返す。さらに範囲を狭めたければ、"site:example.com/pages/"のように、目的のページが含まれるところまで指定することで、そのパターンに合致した結果のみを得ることができる。これはドメインオーナーが公にしてはいるものの、あまり広めたくはない、という情報を探すのに非常に有用であり、正しいキーワードを選ぶことで大変な材料が掘り出せることもある。
ウェブページ、画像、映像
あるウェブサイトそのものではなく、あるストーリーの周辺にみられる活動に興味があるという場合がある。以下にあげるのは、人々がウェブ上のコンテンツをどのように読み、反応し、コピーし、シェアしているかを違った角度から見せてくれるツール群である。
- Bit.ly
-
筆者は人々が特定リンクをシェアしあう様子を知りたいときはいつも bit.ly を訪れる。使うには知りたいURLを入力する。そしてInfo Page+というリンクをクリックする。これにより完全な統計ページが見られる(サインインしている場合は"aggregate bit.ly link"を先に選択する必要がある)。これにより、FacebookやTwitterでの動きを含めてそのページがどのくらい人気があるか感じがつかめ、また下の方にはbacktype.com提供の、そのリンクについての公開討論が見られる。トラフィックデータと人々の会話、という組み合わせは、あるサイトまたはページがなぜ人気であるか、ファンはどんな人であるか、といったことを理解しようとするときに、とても役に立つのだ。実例をあげると、草の根シェアリングとサラ・ペイリンについての広く流布した物語が間違いであるという強い証拠をこの方法で得たことがある。
-
短文投稿サービスが広く使われるにつれて、人々がどのように個々のコンテンツをシェアしたり、そのコンテンツについてどのようにして会話するのかを知るのにそのようなサービスは大変便利な存在となった。今や特定のリンクに関する人々の会話を調べるのは想像以上に簡単にになったのである。あなたのすることといえば、検索ボックスにあなたの調べたいURLをただ貼り付け、さらにせいぜい全ての結果を見るために"more tweets"のボタンを押したりする程度のものだ。
- Googleのキャッシュ
-
ページが議論の的になると、発表者が告知なく取り下げたり改変したりすることがある。この問題を感じたとき、まず見るべきなのはGoogleのキャッシュで、これはクロール時のものが残っているからだ。クロールの頻度は上がり続けているので、改変が疑われる時点から数時間以内であれば最高だ。目的のURLをGoogleの検索ボックスに入れて、結果ページの右にある三角矢印をクリックする。グラフィカルプレビューが出てくるはずで、ラッキーならば上のところに小さく「キャッシュ」と書かれたリンクが付いている。クリックすると、グーグルによるページスナップショットが表示される。うまくロードできないときはフルキャッシュのページのトップにあるリンクでテキストのみのページに切り替えることができる。関連するコンテンツはとりあえずスクリーンショットまたはコピー&ペーストしておいた方がよいだろう。いつまたクロールがあってアクセスできなくなるか知れたものではないからだ。
- The Internet ArchiveのWayback Machine
-
もし、ある特定のページが数カ月数年という長期間にわたってどのように変化してきたかを知りたければ、 Internet Archive が The Wayback Machine と呼ばれるサービスを提供している。これはウェブ上で話題となるページの多くについてスナップショットを定期的に取るサービスだ。そのサイトを訪問して調べたいURLを入力すると、もしスナップショットがあればカレンダーが表示され、調べたい時点を選ぶことができ、おおよそ当時のありのままのページが表示される。スタイルや画像が欠落していることはしばしばだが、当時のページ内容の中心が何であったかを理解するには通常十分である。
- ソースを見る
-
これが役立つことはそうないかもしれないが、開発者はしばしばコメントや他の手がかりをどのページにも付随するHTMLソースに残したりする。ブラウザによってメニュー表示は異なるが、大抵「ページのソースを表示」というメニューを選ぶことで生のHTMLを見ることができる。機械可読可能な部分が何を意味しているかを理解する必要はなくて、ただその周りに散らばるテキスト群をじっくりみてほしい。たとえそれが、ただ著作権表示や他の著者に関する言及であったとしても、ページの作成や目的についての重要な手がかりをしばしば提供してくれる。
- TinEye
-
時々、画像の来歴をどうしても知りたくなることがあるだろうが、明確な帰属表示でもない限り、Google のような伝統的なサーチエンジンではいい方法が見当たらない。 TinEye は「画像の逆検索」機能に特化しており、持っている画像をアップロードすると、ウェブ上にあるとてもよく似た画像を見つけてくれる。マッチングのために画像認識を使っているため、コピーされた画像が切り取られたり歪められたリ圧縮されていたとしても機能する。特に有用なのは、オリジナルだとか新しいとされている画像がそうではないのではないかと疑った場合で、TinEye が本当の情報源へ導いてくれるだろう。
- YouTube
-
ビデオの下にある統計アイコンをクリックすると、時系列に沿った視聴者の充実した情報が得られるだろう。完全ではないが、どの国のどんな人々がいつ見たかといったことを大雑把に把握するのに有用である(訳注:この詳細な統計機能は2016年現在、動画投稿者しか見れないように変更されている)。
Emails
もし、調査しているEメールがあるのならば、送信者が誰かとかどこにいるかといったことを詳細に知りたいと思うことはしばしばあるだろう。これを助けてくれるようなパッと使えるツールは無いが、どのEメールにも含まれている隠されたヘッダーの基礎的なことを知っておくのは大いに有用だろう。これはアナログの郵便でいうところの消印のような役割をしていて、送信者についての情報を驚くほど明らかにしてくれる。特に、このヘッダーにはEメールが送られた機械のIPアドレスが含まれていることが多く、これは電話でのナンバーディスプレイに非常に似ている。そしてそのIPにたいしてwhoisコマンドを走らせることによってその機械をどの組織が所有しているかを見出すことができる。Comcast や AT&T のような企業がその客にインターネットを提供していることが分かったら、次は MaxMind を訪れて、おおよその位置を割り出せばよい。
Gmail でこのヘッダーを見るには、メッセージを開いて、右上の返信の横のメニューを開いて「メッセージのソースを表示」を選ぶ。
そうすると、新しいページに隠された内容が表示される。そこには30行ほどのある語とコロンのペアから始まる情報がある。お目当てのIPアドレスはその中に含まれているだろうが、Eメールの送られ方によってその項目名は異なる。Hotmail ならば、X-Originating-IP: と呼ばれるし、Outlook や Yahoo ならば、一行目に Received: から始まる行があるだろう。
IPアドレスを Whois に投げた結果、それがイギリスのインターネットサービスプロバイダ Virgin Media のものであることが分かった。そして、さらに MaxMind の位置情報サービスに投げることで、私の故郷であるケンブリッジから来ていることが分かった。つまり、このメールが詐欺師ではなくて私の親から実際に送られたものであるということを根拠を以て確信することができるというわけだ!
トレンド
もし、あなたが特定のサイトやアイテムについてではなくむしろ幅広いトピックについて掘り下げたいのならば、洞察を得るのを助けてくれるツールが2つある。
- Wikipedia Article Traffic
-
(訳注:2016年4月現在、このサイトは使えなくなっているが Page view statistics for Wikimedia projects のページから元データを得ることはできる) もしあなたが、トピックや人に関する世間の興味が時系列でどう移り変わってきたかを知りたいならば、実はウィキペディアのあらゆるページについて日毎の閲覧数を stats.grok.se から確認することができる。このサイトは少々ぞんざいだが、少し調べるだけで得たい情報を引き出すことができる。興味ある物事の名前を入力すると、そのページの閲覧数の月間推移を見ることができる。指定した月において一日当たり何回そのページが閲覧されたかがグラフで図示される。残念なことに、一度に一月分しか見れないので、より長い期間の変化を見たければ月をその都度選び直す必要がある。
- Google Insights
-
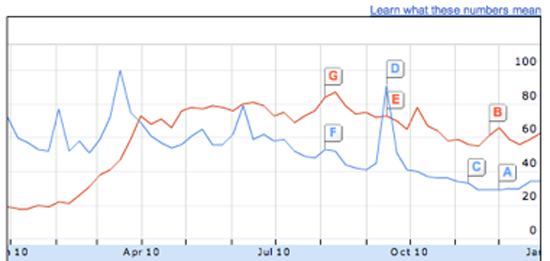
(訳注:これは2016年4月現在 Google Trends として提供されており、機能も大幅に変更されている) Insights from Google (Figure 11) を使えば、人々の検索行動についての明確な情報を得ることができる。"Justin Bieber vs Lady Gaga" のような一般的な検索フレーズを入力すれば、相対的な検索数の時系列グラフを見ることができるだろう。データの見方を調整するためのオプションも豊富であり、狭い地域に限って見たり、より細かい時間スパンで見たりすることができる。ただ一点残念なのは、絶対的な値を得ることができないということだ。相対的なパーセント表示しか得られないため、それを読み解くのには困難を伴う。
— Pete Warden, independent data analyst and developer