データ可視化を利用してデータの中の知見を見つける
可視化はデータ分析において重要だ。攻撃の最前線であり、他の方法では明らかにすることが難しいであろうデータの複雑な構造を提示してくれる。
Hobart Press)
データはそれ自体は、コンピュータに保存されているビットやバイトであり、見ることが出来まない。データを見て理解するためには、それを可視化しなければなりません。ここでは広義の意味で 可視化 という言葉を用いる。ここではデータを単にテキストで再現することも含む。例えば、データセットをスプレッドシート・ソフトウェアにロードすることもデータ可視化と見なす。見ることができないデータが突然スクリーン上に見える"絵"になるのだ。よって、問題はジャーナリストがデータを可視化するか否かではなく、状況に応じてどのような可視化が適しているのかが重要なのである。
言い換えれば、表をつくる以上の可視化が有用なのはいつだろうか?端的な答えは、ほとんどいつもである。表それ自体はデータセットの概観を得るには、まず間違いなく不十分だ。表からはデータの傾向をすぐに見いだすことができない。最も典型的な例は、データを地図上に可視化した場合にのみ見つけることが出来る地理的傾向である。しかし、他の種類の傾向もあるのでこのセクションで後ほど説明する。
可視化を利用して知見を見つける
データ可視化のツールや技術が、閉塞を打ち破ってくれるだろうと期待するのは非現実的だ。それだけではデータセットからストーリーは生まれない。ストーリーを担保してくれるようなルールや"プロトコル"はない。それよりも"知見"を探すために有用で、優秀なジャーナリストの手によって上手くストーリーに織り込まれる。
全ての新たな可視化がデータに関する何らかの知見を与えてくれるだろう。知見のいくつかは既に知られているかもしれないが(しかしおそらくまだ証明されていない)、中には全く新しく驚かせてくれるような知見もあるかもしれない。新たな知見は、ストーリーの始まりを意味するかもしれないし、データにあるエラーの結果かもしれない。これは多くの場合、データ可視化によって見つかるだろう。
データの中にある知見をより効率的に見つけるために、そのプロセスをFigure 4 で(そしてこのセクションの残りで)議論しているのでこれは役立つと思う。
データ可視化の方法を学ぶ
可視化はデータセットに関する特有の視座を与えてくれる。実に様々な方法でデータを可視化できる。
比較的小さな数字のデータを扱うときに、表はとてもパワフルだ。最もはっきりと構成された形でラベルと量を示してもらい、データをソートしてフィルターをかける能力と組み合わせることでその潜在的可能性を最も発揮する。加えて、エドワード・タフテは、例えば表のセルの中に、小さな表を含めたり、行ごとに棒を描いたり、小さな折れ線グラフを作ることを提唱した(それ以来スパークラインと知られている)。これは、一次元的な外れ値、例えばトップ10が何かを知りたいときに有用だ。しかし、複数の次元を同時に比較するときにはあまり役に立たない(例えば時系列で、国ごとの人口を見るときです)。
表というのは、概して、複数次元のデータを描き、幾何学的な形式の見える性質のものにすることだ。個々の視覚的性質の効用については多く書かれており、短く言うとこうなる:色は難しく、位置が全てである。例えば散布図では、二つの次元がxとyの位置で描かれている。さらにシンボルの色やサイズによって第三の次元も表現できる。折れ線グラフは特に一時的な展開を表現するのに向いており、棒グラフは、分類データを比較するのに最適だ。表の要素をそれぞれの上に並べることができる。もしデータの中の小さな数のグループを比較したければ、同じ表の複数事例を表示することがとても強力な方法だ(小さな倍数としても言及される)。全ての表で、異なる種類のスケールを用いてデータの異なる側面を探求できる(例えば、線形やログ)。
事実、私たちが扱うデータのほとんどが、何らかの形で実際の人に関連している。地図の力はデータを私たちのより物質的な世界に再びつなげてくれることである。犯罪事例の地理的データセットを想像してみてください。重要なことは、犯罪が_どこで_起こっているのかを知りたいということである。また地図はデータの地理的関係も明らかにしてくれる(例えば、南北や、都市・地方での傾向)。
関連を語るときに、四番目に重要な可視化の種類はグラフである。グラフとはデータ・ポイント(結節点)の中の相互に関連する場所(接線)を見せることだ。結節点の位置は多かれ少なかれ、複雑なグラフ・レイアウトのアルゴリズムによって計算される。これによって私たちはすぐにネットワークの構造を把握できる。グラフ可視化の技は、概して、ネットワーク自体をモデル化する適切な方法を探すことを見つけることだ。全てのデータセットが何かの関連を含むわけではないが、もし含んでいたとしても、注目する興味深い側面ではないかもしれない。場合によってはジャーナリストが接線と結節点を決めることになる。完璧な例はこれだ。 U.S. Senate Social Graph 接線は同一の票を65%以上投じている上院議員同士を結んでいる。
見ているものを分析し解釈する
データを可視化したら、次のステップは自分で作った絵から何かを学ぶことだ。自分自身にこう問うかもしれない。
-
この映像から何が見えるだろうか?それは自分が期待していたものだろうか?
-
何か興味深い傾向があるだろうか?
-
データの文脈においてそれは何を意味するのだろうか?
時折、可視化をしたものの、見た目が美しいだけで、何もデータについて興味深いことを見つけることが出来ないかもしれない。しかし、ほとんどの場合、些細なことではあるかもしれないが可視化から 何か を学ぶことが出来る。
知見とステップを文書化する
このプロセスをデータセットの旅と考えるならば、ドキュメンテーションは旅日記である。旅日記を見れば、どこをこれまで旅し、そこで何を見て、次の一歩をどのように決めたかがわかるだろう。データを最初に見るよりも前に、ドキュメンテーションをスタートすることだってできる。
見たことのないデータセットに取り組みはじめる、その多くの場合において、データに対して私たちは期待や前提に満ちた状態である。通常、私たちが見るデータセットに何故興味を持っているかには理由がある。こういった最初の考えをドキュメンテーションに書き留めておくことは良いアイディアである。最初に何を見つけようとしていたのかを探すことで、私たちのバイアスを特定することや、データを誤って解釈してしまうリスクを減らすことに一役買うことになる。
私はドキュメンテーションこそがプロセスの中で最も重要なステップだと思っている。そして、私たちが最も無視してしまいがちなものでもある。以下の例で見るように、叙述のプロセスは描写やデータ論争を引き起こすものである。過去に作った15の図表を見ることは混乱を招くものであろうし、特に少し時間が経つと尚更である。実際、そういった図表が(あなた自身や、発見を伝える他の人々にとって)価値があるのは、その図表自体が作られた文脈において見せられた場合のみである。よって、以下のような但し書きをするために時間を使うべきである:
-
なぜ私はこの図表を作ったのか?
-
それを作るためにデータに何をしたのか?
-
この図表は何を示しているのか?
データを加工する
ビジュアライゼーションから集めたインサイトがあれば、自然と次に何が見たいか、ということについての考えを持つことになるだろう。より深く調べたいと思うデータセットの中にいくつかの興味深いパターンを見つけているかもしれない。
ありうるデータ加工は以下のようなものだ:
- ズーミング
-
ビジュアライゼーション内の特定の詳細を見ること
- アグリゲーション
-
多くのデータのポイントを、単一のグループにまとめること
- フィルタリング
-
主要な焦点ではないポイントを(一時的に)削除すること
- 異常値排除
-
データセットの99%の代表値ではない単一のポイントを省くこと
グラフをビジュアル化したところで、そこから数百ものエッジを通って接続されたノード以外の何者も生まれなかった場合のことを考えてみよう(いわゆる「密度の高いネットワーク」をビジュアル化したときにはごく一般的なことである)。よくある加工のひとつは、エッジのうちのいくつかをフィルタリングすることである。もし、例えば、エッジが供与国から受領国へのお金の流れを表しているのだとすれば、一定の金額以下の流れをすべて削除することができる。
どのツールを使うべきか
ツールに関する質問は簡単ではない。利用可能なデータ・ビジュアライゼーションのツールは、どれも何かに秀でている。ビジュアライゼーションやデータ加工は簡単で、安価であるべきである。もしビジュアライゼーションのパラメーター変更に何時間もかかっているようであれば、実験にそこまでの時間はかけることにはならないだろう。それは必ずしも、ツールの使い方を学ぶ必要がない、ということを意味しない。しかし、一度学んでしまえば、それは非常に効果的であろう。
データ加工とデータ・ビジュアライゼーションの問題を包含するツールを選ぶことは意味のあることだ。異なるツールで違う作業をすることは、データを頻繁にインポートしたりエクスポートしたりする必要があることを意味する。データビジュアライゼーションとデータ加工のツールのリストを少し紹介しておく:
-
LibreOfficeやExcel, Google Docsのようなスプレッドシート
-
R (r-project.org)やPandas (pandas.pydata.org) のような静的なプログラミングフレームワーク
-
Quantum GIS, ArcGIS, GRASSのような地理情報システム
-
d3.js (mbostock.github.com/d3), Prefuse (prefuse.org) や Flare (flare.prefuse.org)のようなビジュアライゼーションライブラリ
-
Google RefineやDatawranglerのようなデータ加工ツール
-
ManyEyes や Tableau Public (tableausoftware.com/products/public)のような非プログラミング系のビジュアライゼーションソフトウェア
次のセクションのビジュアライゼーション・サンプルはRを使って制作されたものである。Rは(科学的)データ・ビジュアライゼーションにおいて万能なものである。
例:米国選挙の寄付金データの意味
アメリカの大統領候補に対する450,000もの寄付を含む、米国の大統領選の財務データベースを見てみよう。CSVファイルは60メガバイトで、Excelのようなプログラムで簡単に扱うには大きすぎる。
最初のステップでは、FECの寄付金データセットにおける最初の仮定を明確に書き下すことにする:
-
Obamaは最も寄付を集めている(なぜなら彼は大統領であり、最大の人気がある)
-
寄付の数は選挙日が近づくにつれ増えていく
-
Obamaは共和党員よりも少額の寄付をたくさん集めている
最初の質問に答えるため、データを_加工_する必要がある。ひとつひとつの寄付ではなく、各候補者への寄付された額の総額を計算する必要があった。整理されたテーブルの結果を_ビジュアル化_したあと、Obamaがほとんどの金額を集めただろうという仮定が確実なものとなる:
| 候補者 | 金額 (USD) |
|---|---|
Obama, Barack |
72,453,620.39 |
Romney, Mitt |
50,372,334.87 |
Perry, Rick |
18,529,490.47 |
Paul, Ron |
11,844,361.96 |
Cain, Herman |
7,010,445.99 |
Gingrich, Newt |
6,311,193.03 |
Pawlenty, Timothy |
4,202,769.03 |
Huntsman, Jon |
2,955,726.98 |
Bachmann, Michelle |
2,607,916.06 |
Santorum, Rick |
1,413,552.45 |
Johnson, Gary Earl |
413,276.89 |
Roemer, Charles E. 'Buddy' III |
291,218.80 |
McCotter, Thaddeus G |
37,030.00 |
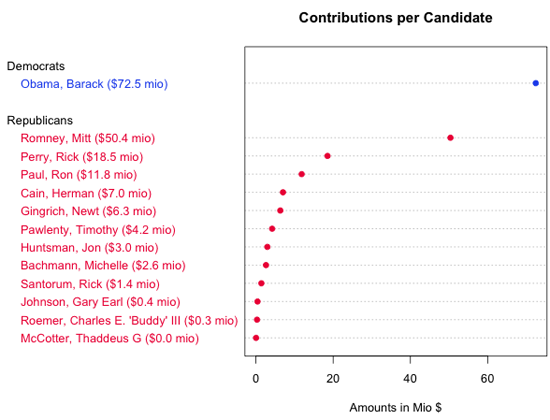
この表は最少額・最高額と順序を示しているものの、候補者の順位の裏に流れるパターンについてわかることは少ない。 Figure 7 はデータを別の観点から見たものである。ドット・チャートと呼ばれるタイプの図表であるが、これで表に現れたもの だけでなく 表の中のパターンを見ることができる。例えば、ドット・チャートによってObamaとRomney,の距離、Romney,とPerry,の距離をすぐに比較することが、値を抜き出すことなく容易になる。(注:このドットチャートはRを用いて作られた。この章の末尾にソースコードへのリンクがある)
では、データセットのより大きな視点へと進もう。最初のステップとして、時間とともにすべての寄付金額をシンプルなプロットの中に_ビジュアル化_した。3つの実に大きな異常値に比べ、ほとんどの寄付はごくごく小さいものであることが見て取れる。より深く調べてみると、これらの大きな寄付は "Obama Victory Fund 2012"(Super PACとしても知られている)から来ており、6月29日(450,000ドル)、9月29日(1,500,000ドル)、12月30日(1,900,000ドル)のことであることがわかる。
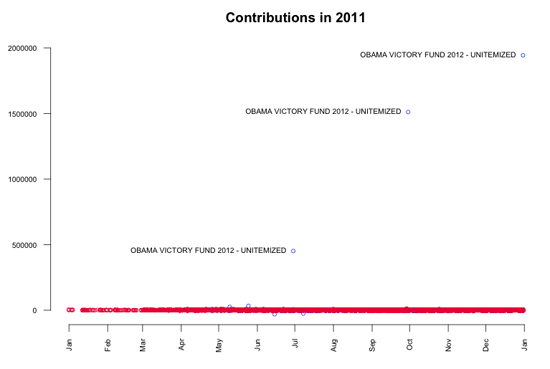
Super PACs単体による寄付はデータにおいて疑いようのない大きなストーリーであるが、それを越えてデータを見てみるのもまた興味深い。ここでのポイントは、これらの大きな寄付によって、個人からの小さな寄付に着目できなくなっていることであるので、それらをデータから取り除くことにする。この加工は異常値除去として知られている。もう一度ビジュアル化してみると、ほとんどの寄付が5,000ドルから10,000ドルの間であることがわかる。
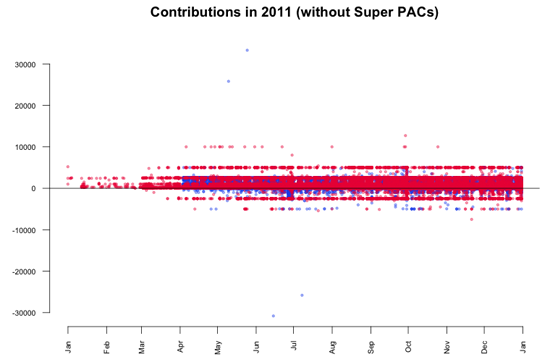
FECAによって定められている寄付の限度によると、個人は各候補者に対して2,500ドル異常を寄付することを認められていない。プロットの中に見られるように、限度を越えて行われた寄付が多数ある。特に、5月の2つの大きな寄付が目を引く。これらは6月と7月にマイナス金額で相殺(返金)されているようだ。さらなる調査をデータに行うことで、以下の取引も明らかになる:
-
5月10日、San FranciscoのBanneker Partnersに雇用されている弁護士_Stephen James Davis_がObamaに25,800ドル寄付
-
5月25日、Little RockのMurphy Groupに雇用されているPR_Cynthia Murphy_がObamaに33,300ドル寄付
-
6月15日、_Cynthia Murphy_に30,800ドル返金。これにより、寄付額が2,500ドルまで減額
-
7月8日、_Stephen James Davis_に25,800ドル返金。これにより、寄付額が0ドルまで減額
これらの数字で興味深い点はなんだろう?Cynthia Murphyに返金された30,800ドルは、National Party Committeeに1年で譲渡しても良い個人の金額に等しい。おそらく、彼女は両方の寄付をひとつの送金で済ませたかったのだが、拒否されてしまった。Stephen James Davisに返金された25,800ドルは、おそらく30,800ドルから5,000ドル(他の政治的委員会への寄付金額の限度額)を引いたものに等しい。
最後のプロットから導き出せるもうひとつの興味深い発見は、5,000ドルと-2,500ドルにある共和党候補への寄付にある水平の直線パターンである。それらをより詳細に見るため、共和党への寄付だけをビジュアライズした。結果のグラフは、データにおけるひとつの大きなパターンの例であり、データ・ビジュアライゼーションなしには見えないものであろう。
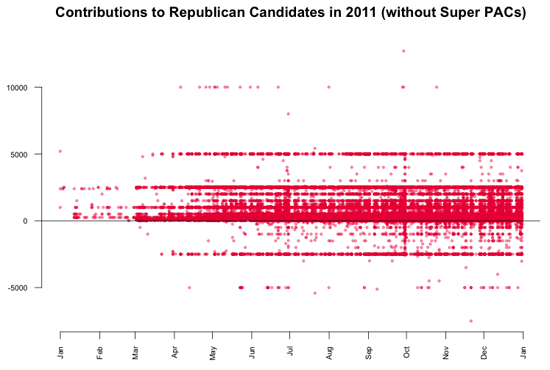
共和党候補への5,000ドルの寄付が数多くあることが見てとれる。事実、データに戻って見てみると、1,243件の寄付があり、それは全体の0.3%に過ぎないのであるが、時間軸に沿って均等に行われているため、直線が現れるのである。この直線の興味深い点は、個人からの寄付が2,500ドルまでに制限されていたことだ。結果として、限度を越えた額はすべて寄付者に返金され、それが-2,500ドルの直線になっているのである。反対に、Obamaへの寄付には同様のパターンが見られない。
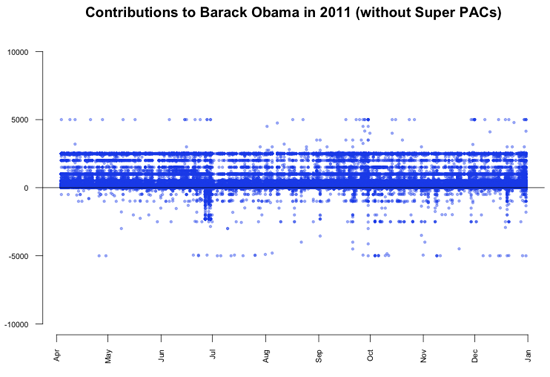
数千もの共和党への寄付者が、個人の寄付の限度額に気づかなかった理由について知ることは興味深いだろう。この件についてさらに分析するため、候補者ごとの5,000ドルの総寄付件数を見てみよう。
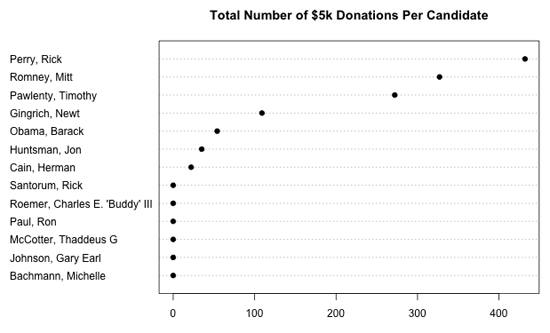
もちろん、各候補者の受け取った総額を考慮していないので、これは少し捻じ曲がった見方である。次のプロットで、候補者ごとの5,000ドルの寄付をパーセンテージで見てみよう。
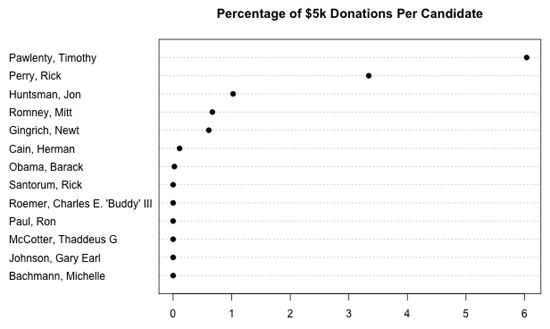
ここからわかること
しばしば、このような新しいデータセットのビジュアル分析は知らない国へのエキサイティングな旅のように感じられる。データと仮説に対して何も知らない人としてスタートし、一歩一歩進み、図表を描くごとに、そのトピックについて新たな洞察を得ることになる。それら洞察にもとづき、次の一歩を決め、さらなる調査に値する問題が何かを決めていくのだ。この章で見てきたように、データのビジュアル化、分析、改変のプロセスは、ほとんど永遠に続くものなのである。
ソースコードを手に入れる
この章で紹介したすべての図表は、素晴らしくまたパワフルなソフトウェア「R」によって作成された。主に科学的ビジュアライゼーションツールとして作られているが、Rに実装されていないビジュアライゼーションやデータ加工のテクニックを見つけることは難しい。Rを用いてデータのビジュアル化や加工に興味がある方々向けに、この章の図表を作るのに使ったソースコードを掲載する:
様々な書籍やチュートリアルもある。
— Gregor Aisch, Open Knowledge Foundation