データ・ジャーナリズムの展望
2010年の8月、私とヨーロッパ・ジャーナリズム・センターの数人の同僚たちは、 おそらく世界で初めてのデータ・ジャーナリズム会議をアムステルダムで主催した。当時このトピックに関してさほど多くの議論がなされていない状態で、この分野での仕事で広く知られた組織はほんの2、3しかなかった。
データ・ジャーナリズムという言葉を知らしめた大きな一歩の一つに、the GuardianやThe New York Timesといった報道機関がWikiLeaksによって公開された大量のデータを扱ったことがある。当時データ・ジャーナリズムという言葉は、ジャーナリストがデータを活用して取材範囲を拡充し、特定の話題についての掘り下げた調査を補う手法を説明するのに、「コンピューター支援報道(computer-assisted reporting)」という言葉とともに以前より広く使われ出した。
経験豊かなデータ・ジャーナリストやジャーナリズムの研究者に Twitterで 聞いてみたところ、今我々がデータ・ジャーナリズムとして認識しているものを最初期に定義したものの一つは、ユーザがある地域、街区で起きていることを調べられるようにする情報サービスEveryBlockの創始者であるAdrian Holovatyによって2006年になされたものであるようだ。 「新聞サイトは根本的に変わるべきだ」 という彼の短いエッセイにおいて、彼はジャーナリストは従来の「大きな文章の塊」だけでなく、構造化され、機械可読なデータを公開すべきだとし、以下のような主張を行った。
例えば、新聞が地方の火事の記事を書く場合を考える。携帯電話でその記事を読めるのは結構なことだ。テクノロジー万歳! でも本当にできてほしいのは、何層もの属性からなるその記事の未加工な事実を一つずつ探ることであり、火事が起きるたびに、その火事の詳細――日付、時刻、場所、犠牲者、消防署の番号、消防署からの距離、かけつけた消防士の名前や勤続年数、消防士の到着にかかった時間――を過去に起きた火事の詳細と比較することのできる基盤が欲しいのだ。
しかし、データ・ジャーナリズムはデータベースやコンピュータを用いた他の形のジャーナリズムに比べて、なにが特別なのだろう?どのように、そして、どの程度、データ・ジャーナリズムは過去のジャーナリズムの形式から異なっているのだろう?
「コンピューター支援報道」と「精度ジャーナリズム」
データを活用して報道記事の質を高め、一般に公開されている(機械可読ではないにせよ)構造化された情報を伝えることには長い歴史がある。我々が今データ・ジャーナリズムと呼ぶものとおそらくもっとも直接関連があるのは、「コンピューター支援報道(computer-assisted reporting、CAR)」である。これは、コンピュータを使ってデータを収集、分析して報道の質を高める最初の系統的で秩序だったアプローチだった。
CARという言葉は、1952年に大統領選挙の結果を予測するのにCBSによって初めて使われた。1960年代以降、(主に調査に携わる、主に米国を基盤とする)ジャーナリストが公文書のデータベースを科学的手法で分析し、自主的に権力を監視しようとしてきた。これは「公共ジャーナリズム」としても知られるが、こうしたコンピューター支援技術の支持者はトレンドを明らかにし、一般に広まっている知識の誤りを暴き、公共機関や民間会社により行われた不正行為を明るみにしようとしてきた。例えば、Philip Meyerは、1967年にデトロイトで起きた暴動に関する一般的な見解の誤りを暴こうとした――暴動に参加していたのが教育水準の低い南部人だけではないのを示したのだ。1980年代におけるBill Dedmanの「The Color of Money」の記事は、主要金融機関の融資方針に広まる人種偏見を暴露した。Steve Doigは「What Went Wrong」において、1990年代初期のハリケーン・アンドリューによる被害の分布を分析し、欠陥のある都市開発政策やその運用の影響を知ろうとした。データ駆動型の報道は有益な公共サービスをもたらし、高名なジャーナリストの賞を獲得した。
1970年代初期、「社会科学や行動科学の研究手法をジャーナリズムの実践に応用する」取材方法を表現するのに「精度ジャーナリズム(precision journalism)」という言葉が発明された。精度ジャーナリズムは、ジャーナリズムや社会科学の教育を受けた専門家によって、メインストリームの報道機関で実践されることを想定したものである。精度ジャーナリズムは「ニュー・ジャーナリズム」に応えて生まれたものだが、ニュー・ジャーナリズムとは創作のテクニックを報道に応用したジャーナリズム形態である。Meyerは、客観性や真実の探求を成し遂げるには、文学技法ではなくデータを集め分析する科学的技法こそがジャーナリズムに必要なものなのだと語る。
精度ジャーナリズムは、ジャーナリズムの欠点や弱点としてよく言われるものの一部に対する答えと考えられる。それは報道発表への依存(後に「チャーナリズム(churnalism)」と言われるようになる)、権威筋寄りの姿勢などである。これらをMeyerは、世論調査や公文書などへの情報科学技術や科学的手法の応用が足らないことから生じていると見ている。1960年代に予想されたように、精度ジャーナリズムは社会の周縁にいる人たち、そして彼らの話を伝えるのに使われた。 Meyer は以下のように語る。
精度ジャーナリズムは、ジャーナリズムの調査に関して、それ以前は手が届かなかったかほとんどアクセスできなかった話題を作り出すために記者のツールキットを拡張する手段だった。それは権利を求めて闘っていたマイノリティや反体制派に意見表明の機会を与えるのに特に有用だった。
1980年代に出版されたジャーナリズムと社会科学の関係についての 影響力の大きな記事 は、現在のデータ・ジャーナリズムを巡る話を先取りしている。記事の著者である二人のアメリカ人のジャーナリズムが専門の教授は、1970年代と1980年代、大衆が考えるニュースは、狭義の「ニュースとなる出来事」から「状況に対応した報道」や社会的傾向に関する報道まで広がっていることを示唆している。例えば、国勢調査データのデータベースを活用して、ジャーナリストは「特定、単独の出来事の報道からあるコンテキストに意味を与えるところまで進む」ことができるわけだ。
お分かりの通り、報道の質を高めることを目的とするデータの活用は、「データ」の歴史まで遡るのだ。Simon Rogersが指摘するように、the Guardianにおけるデータ・ジャーナリズムの最初の実例は1821年に遡る。それはマンチェスターの学校における出席した生徒数と学校あたりの経費を記載した表が漏洩したものである。ロジャースによると、これが無償で教育を受けている生徒の実数を初めて明らかにし、それが公表されている数字よりずっと多いことが分かる助けとなったというのだ。
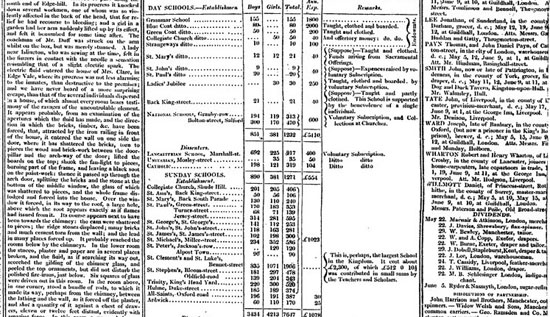
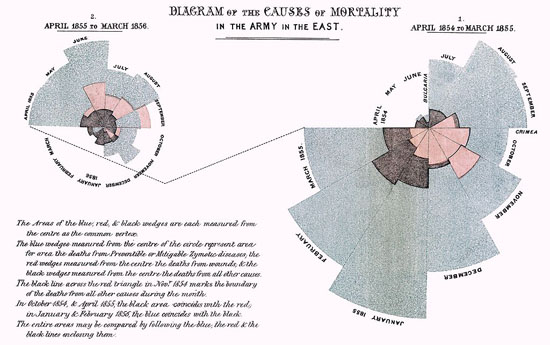
もう一つヨーロッパにおける初期の例に、Florence Nightingaleと1858年に公開された彼女の重要なレポート 「英国陸軍の死亡率」 がある。議会に向けたレポートで彼女は、グラフを用いて英国陸軍における医療サービスの改善を訴えている。最も有名なのは彼女が「鶏のとさか」と呼ぶ円グラフで、これは月毎の死者数を示しており、その死の大部分が銃弾ではなく避けられたはずの病気によるものであることを強調するものだった。
データジャーナリズムとコンピュータ支援報道
現在、「データ・ジャーナリズム」という標語と、コンピュータ技術を用いてデータセットを分析する以前からあるジャーナリズムの実践とデータ・ジャーナリズムとの関係をめぐり、それが「過去から続くものか変化したものか」の論争が続いている。
CARとデータジャーナリズムの間には違いがあると主張する人たちもいる。彼らによれば、CARは(通常、調査)報道を強化する手段としてデータを集め分析する技術なのに対し、データ・ジャーナリズムはデータがジャーナリズムのワークフロー全体に入り込む手法に留意しているというのだ。この意味においてデータ・ジャーナリズムは、ストーリーを見つけたり強化したりする一手段としてだけデータを利用するのではなく、データそのものにストーリーと同じくらい――時にはストーリーより――気を配っている。だから、the GuardianのDatablogやthe Texas Tribuneは、記事とともにデータセットを公開するのであって、人々が分析して探求できるようデータセットだけ公開することさえある。
それ以外にも異なる点がある。今までの調査報道のジャーナリストは、答えようとしている問いや取り組もうとしている事柄に関する情報不足に悩まされていた。その事自体は今でも変わっていないものの、ジャーナリストがどう扱ってよいかわからなくなりそうなほど圧倒的に豊富な情報も存在するようになった。彼らはデータからどうやって価値を引き出せばよいか分からないのだ。最近の例を挙げると、Combined Online Information System (統合オンライン情報システム)というイギリスで最大の消費情報のデータベースがある。このデータベースは情報公開を唱える人々にとって長年の夢だったわけだが、公開と共に多くのジャーナリストを当惑させ、困らせた。Philip Meyerは最近私に次のような言葉を書いてよこした: 「情報が不足している時には、私たちの努力のほとんどは情報を狩り、集めることに費やされていたものだよ。いまや、情報は溢れかえり、処理が一番大事になった。」
一方で、データ・ジャーナリズムとコンピュータ支援報道には大した違いはないと主張する向きもある。最も最近のメディアにおける実践にさえ歴史があるのは、その中に何かしら新しいものがあるのと同じくらい今では常識である。データ・ジャーナリズムがまったく新しいものかどうかを議論するよりも、それが歴史のある伝統の一部なのか、新しい環境や条件に対する反応なのか考えるほうがより実がある姿勢だろう。たとえ目標や技術に違いがなくとも、今世紀はじめに「データ・ジャーナリズム」という標語が生まれたのは、洗練されたユーザ中心のツール、自主出版やクラウド・ソースのツールとともにオンラインで無料で公開される膨大な量のデータにより、より多くの人たちがかつてよりもずっと容易により多くのデータに取り組める新しいフェーズに入っていることを示している。
データ・ジャーナリズムには大量データ・リテラシーが必要
デジタル技術とウェブは、情報が公開されるあり方を根本的に変えつつある。データ・ジャーナリズムは、データ・サイトとサービスの周りで生まれてきたツールや実践のエコシステムの一部である。源資料の引用、共有は、ウェブのハイパーリンク構造の本質だし、我々が今日情報のナビゲートを常習的に行うやり方でもある。さらに掘り下げると、ウェブのハイパーリンク構造の土台にあるのは、アカデミズムの世界で採用されている引用の原則である。源資料の引用、共有や記事の背景にあるデータは、ウィキリークスの創始者ジュリアン・アサンジが「科学的ジャーナリズム」と呼ぶ、データジャーナリズムがジャーナリズムを向上させうる基本的な方法の一つなのだ。
誰もがデータ・ソースを掘り下げ、それに関連する情報を見つけられるようにし、主張を検証して一般に受け入れられている前提を疑えるようにするという意味で、データ・ジャーナリズムはかつては専門家――事件記者、社会科学者、統計学者など――に利用された情報源、ツール、テクニック、方法論の大衆民主化を象徴するものである。現状ではデータ・ソースの引用やリンクがデータ・ジャーナリズムを特徴づけているが、我々はデータがメディアの仕組みにシームレスに統合された世界に向かって進んでいるのだ。データ・ジャーナリストは、データを理解し詮索する障壁を下げるのを助け、世界的に読者のデータ・リテラシーを高めるという重要な役割を担っている。
今のところ、データ・ジャーナリストを自称する人々の萌芽的コミュニティは、より成熟した CAR のコミュニティとほとんど重複していない。願わくは、将来的には、ProPublica や Bureau of Investigative Journalism (調査報道事務局) のような 市民メディア組織 や 新しい NGO が調査において伝統的なニュース・メディアと手を取り合って協働しているのと同じような形で、これら2つのコミュニティの間に強い結びつきができればよいと思う。データ・ジャーナリズムのコミュニティはデータを届けストーリーを描き出すのにより革新的な方法をもっているかもしれないが、CAR のコミュニティが持っている深い分析や批判的なアプローチはデータ・ジャーナリズム側が学べる部分だ。
— Liliana Bounegru(European Journalism Centre)