ウェブからデータを得る
もしあなたがあらゆる方法を試行してみたものの、データにまだ手が届かずにいる。またはウェブ上にデータは見つかったものの、悲しいかな、ダウンロード可能でなかったり、コピー&ペーストできない状態だったとする。大丈夫、そこからデータを取り出す方法はまだあるかもしれない。例えば次のような手段がありえる:
-
WebベースのAPI経由でデータを取得する。オンラインデータベースやモダンなWebアプリケーション(Twitter、Facebookなど多数ある)がインターフェースを提供している場合がある。ソーシャルメディアサイトと同様、政府が公開するデータや商用データにアクセスする有力な方法である。
-
PDFファイルからデータを抽出する。この方法は難しい。PDFはもともとプリンタ向けの言語であり、文書に含まれるデータ構造のための情報を多く持てないためである。PDFファイルからの情報抽出は本書で扱う範囲外ではあるが、世の中のいくつかのツールやチュートリアルが役に立つかもしれない。
-
Webサイトをスクリーンスクレイピングする。それが可能なユーティリティを用いる、または簡単なコードを書くことにより、通常のWebページから構造化された内容を抽出する。とても強力な方法で多くの場合に適用できる方法だが、Webそのものの仕組みをある程度知る必要がある。
このようなすばらしい技術的な選択肢とともに、簡単な方法も忘れてはならない:機械可読なデータを持つファイルの検索に時間を使ったり、あなたが望むデータを持っている組織に問い合わせたりすることにも価値がある。
この章では、HTMLで書かれたWebページからデータを取得する基本的な例を紹介する。
機械可読データとは?
これら方法のほとんどの目的は、機械可読データへのアクセスである。機械可読データとは、人間が読める形かどうかにはかかわらず、コンピュータ処理のために生成されるデータのことである。このようなデータの構造は、含まれる情報に関連し、表示のされ方には関連しない。機械可読フォーマットの代表例はCSV、XML、JSON、Excelファイルである。一方、Word文書やHTMLページ、PDFファイルは、文書の視覚的なレイアウトと関係が深い。例えばPDFはプリンタへ直接情報伝達する言語であり、判別可能な文字よりも、ページ上の線や点の位置により大きく関わっている。
Webサイトのスクレイピング:目的は?
皆これはすでに実践していることだ。すなわち、Webサイトを訪れ、その中のある表に興味を持ち、Excelファイルへコピーする。そうすることでいくつか数値を集計したりのちのために保存しておくこともできる。しかし実際はこの方法はあまり有効ではない。あなたが望むデータはたくさんのWebサイトにまたがって存在することもある。手動でのコピー作業はすぐに退屈になるだろう。なのでちょっとしたコードを使うのが理にかなっているのだ。
スクレイピングの利点は、天気予報から政府支出まで、たとえ生データへアクセスするAPIが提供されていなくても、実質的にあらゆるWebサイトに対して有効な点にある。
スクレイプできる/できない内容
スクレイプできる内容にはやはり制約がある。スクレイプを難しくする点はいくつかある:
-
構造情報がわずかな(または存在しない)、不適切に整形されたHTMLコード(昔の政府のWebサイトなど)
-
自動アクセスを避けるため設置された認証システム(CAPTCHAコードや有料コンテンツ)
-
ユーザー行動を追跡するためブラウザのCookieを使用する、セッションベースのシステム
-
ワイルドカード検索の可能性および完全な一覧表示の不足
-
サーバー管理者によるバルク・アクセスのブロック設定
もう一つの制約は法の壁である:国によっては、データベースの権利を重要視しており、オンライン化された情報の再利用について、あなたの権利が制限される可能性がある。あなたがジャーナリストとしての特権をお持ちであれば、その権限によっては、ライセンスを見なかったことにして再利用の強行も可能かもしれない。自由に利用可能な政府のデータのスクレイピングは問題ないが、その結果の公表前には二重チェックが必要かもしれない。営利団体およびいくつかのNGOはその点では寛容でなく、自分たちのシステムを「妨害」していると訴えてくる可能性もある。他にも、得た情報によりプライバシーが侵害され、データ・プライバシーに関する法律や職業倫理を犯す可能性もある。
スクレイプに役立つツール
Webサイトからの情報抽出に使えるプログラムは、ブラウザ拡張機能やWebサービスを含め数多くある。ブラウザによっては Readability (ページからテキストを抽出する)や DownThemAll (一度にたくさんのファイルをダウンロードできる)などによって、退屈な手動作業を自動化できる。Chromeの拡張機能である Scraper extension はWebサイトにあるテーブルを抽出するために作成された。FireFoxの開発者向け拡張機能 FireBug (同様の機能はChrome、Safari、IEにすでに存在する)を用いれば、Webサイトがどのように構築され、ブラウザとサーバがどのような通信を行うかを明確に追跡できる。
ScraperWiki は、Python、Ruby、PHPなどさまざまな言語でスクレイパーを記述するのに役立つWebサイトだ。コンピュータ上にプログラミング環境を準備する時間はないけれど、スクレイピングは行いたい、という場合にこのサイトは便利である。GoogleスプレッドシートやYahoo! Pipesなど他のWebサービスも、別のWebサイトからの抽出に役立つだろう。
Webスクレイパーが動作する仕組み
Webスクレイパーは多くの場合、Python、Ruby、PHPのようなプログラミング言語で記述されたコードの小さな集まりである。適切な言語の選択は、あなたがどのコミュニティに属しているかによる:あなたと同じニュースルームや都市に、すでにある言語を使って作業している人がいれば、その同じ言語を使うのがよいだろう。
先に述べたようなポイント・アンド・クリック型のスクレイピング・ツールは、手始めには有用である。一方、Webサイトのスクレイピングにおける実際の複雑さは、必要な情報を抽出するために、適切なページ、およびページ中の適切な要素を対応づける点にある。この作業はプログラミングではなく、Webサイトとデータベースの構造の理解することと言える。
Webサイトを表示するとき、ブラウザは2つの技術を使用している。1つはHTTPで、Webサーバーと通信し、文書や画像、動画など必要なリソースを要求する。もう1つはHTMLで、Webサイトを構成する言語である。
Webページの解剖
HTMLページは、HTML「タグ」で定義される箱型領域の階層構造によって定義される。大きな箱の中には、たくさんの小さな箱が入る。多くの子要素(列とセル)を持つテーブルがその一例である。タグの種類は多く、箱やテーブル、画像、リンクの生成など、それぞれが異なる機能を持つ。タグはその他に付加的な属性を持つこともでき、他と重複しない識別子を与えられる。また「クラス」と呼ばれるグループに含めることも可能で、これにより文書中のどの要素であるかを特定できる。要素を適切な選択と内容抽出、これがスクレイパーを作成する際の鍵となる。
Webページ中の要素を眺めると、あらゆる部分が箱形領域の組み合わせから成っていることがわかる。
Webページをスクレイプするには、HTML文書に含まれる、性質の異なるいくつかの要素について知っておくとよい。例えば <table> 要素はテーブル全体を定義し、 <tr> (table row) は列要素、 <td> (table data) は行方向のセル要素を定義する。もっともよく見かけるであろう基本的な要素は <div> で、これは単純に内容のひとかたまりを定義する。ブラウザ上で developer toolbar を使用すると、簡単に、これら要素が並ぶ様子を確認できる。Webページがどのような構成で成り立ち、どのようなコードで書かれているのかがわかる。
タグはブックエンドのように機能する。まとまりの開始部分と終了部分にマークする。例えば <em> はイタリック体や強調表示にするテキストの開始部分に置かれ、 </em> はその終了部分に置かれる。簡単である。
例:Pythonを用いた原子力事故のスクレイピング
NEWS は、全世界での放射能事故の情報を集めた国際原子力機関(IAEA)のポータルサイトである(そして奇天烈肩書き同好会ののメンバーの座を奪い合う強力な競争相手でもある!)。そのWebページには、事故の一覧がシンプルに、スクレイプが容易なブログ形式で表示されている。
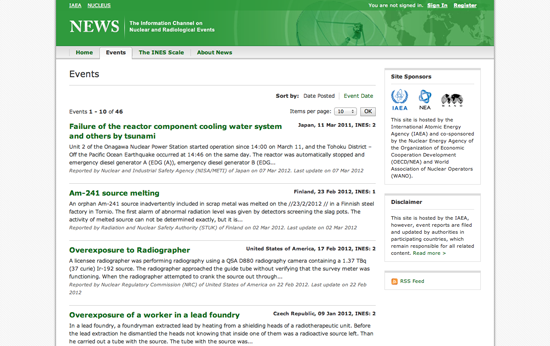
まず、 ScraperWiki 上でPythonによるスクレイパーを作成する。折りたたまれたコードを少し含む以外はほとんど空であるテキスト領域が表示される。別のブラウザウィンドウで IAEA のサイト を開き、ブラウザの開発者メニューを開く。「Elements(要素)」ビューで、ニュース記事を1つ選び、HTML要素の中でそのニュースのタイトルが書かれた部分を探す。ブラウザの開発者メニューにより、Webページの要素とHTMLコードとを結びつけることができる。
このページを調べて見ると、ニュースのタイトルは <table>.の中にある <h4> 要素に含まれていることがわかる。また、<tr> の 並びがそれぞれの放射能事故に対応しており、事故の詳細や日付の情報がこの<tr>に含まれている。すべての事故のタイトルを抽出したい場合は、title要素中にある全テキストを表の各行に連続アクセスして取得してくる必要がある。
これらの処理をコードに落とし込むためには、まず必要な手順が本当にその処理の中にすべて含まれているかどうかを確認する必要がある。これらの処理のためにどんな手順が必要かを理解するために、次のようなシンプルなゲームをしよう:まずあなたのScraperWikiウィンドウにスクレイパーがどのような処理を重ねていけばよいか、料理レシピに書かれている指示文のように、順を追った自分向けの手順を書いてみよう。(Pythonであれば、実行コードでないことを示すため、各行の先頭にハッシュ記号を入れておくとよい)例えば:
#テーブル中の全ての列を探す # Unicorn must not overflow on left side.(Unicornは左側にあふれないように)
できるだけ細かい手順で書くことを勧める。プログラムは、スクレイピング対象のページ内容をすべて知っているわけではない。
ある程度疑似コードで書き出したら、次はその疑似コードと今回のスクレイピングで実際使うコードを比較してみよう:
import scraperwiki from lxml import html
この最初の項目では、ライブラリから既存機能−あらかじめ書かれたコードのスニペット( 切れ端)−をインポートしている。まず scraperwiki をインポートすることでWebサイトのダウンロードが可能となる。また、lxml をインポートすることでHTML文書の構造を分析することが可能となる。いいお知らせ:ScraperWikiでPythonスクレイパーを書いているならこの2行は常に変わらない。
url = "http://www-news.iaea.org/EventList.aspx" doc_text = scraperwiki.scrape(url) doc = html.fromstring(doc_text)
次の上記のコードは url という変数を作成し、IAEAのページのURLをその値として代入している。これによってこれからこのURLに着目するのだということをスクレイパーに伝えることができる。またこのURLは引用符に囲まれているが、この引用符によりURLは実行コードの一部ではなく、 文字列 つまり一連の文字の並びとして扱われることになる。
そして url 変数を入力として関数 scraperwiki.scrape に渡す。関数は定義された処理—この場合はWebページのダウンロードを行う。終了後の出力結果を別の変数 doc_text に入れる。doc_text にはWebサイトに含まれる実際のテキストが入る。つまりブラウザで見えている内容ではなく、全てのタグを含むソースコードである。このフォームはパースがあまり簡単ではなく、各要素の対応付けが容易になるような特別な表現、いわゆるドキュメント・オブジェクト・モデル(DOM)を生成する別の関数 html.fromstring を用いる。
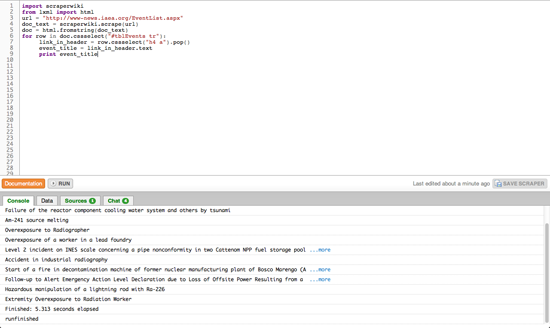
for row in doc.cssselect("#tblEvents tr"):
link_in_header = row.cssselect("h4 a").pop()
event_title = link_in_header.text
print event_title
最後に、DOMを使用することで表から各行を探し出して、各行のヘッダーから事故のタイトルを抽出する。ここでは新たな2つのコンセプトが使われている:すなわちfor ループと要素選択 (.cssselect) の2つである。まずforループの処理についてだが、これはその名前が示す通りのものである。すなわち、まず初めに一時的なエイリアス(この場合は row )をリストの中の項目に対して割り当て、その後に(for文の下の)インデントされたコードを実行するといった処理を各項目リストに対し逐次的に行うのである。
もう1つの新しいコンセプト、すなわち要素選択は文書中から要素を探し出すために、ある特別な言語を活用するテクニックである。その特別な言語とはCSSセレクタと呼ばれ、通常はHTML要素へのレイアウト情報付加に使われるのだが、ページから要素を抜き出すのにも使うことができる。今回の場合は(6行目で) #tblEvents tr を選択しているが、これはテーブルのなかの+<tr>要素の中からID +tblEvents (ここでのハッシュ記号はIDであることを示している)をもつものをマッチングさせる。この処理の結果取得できるのは <tr> 要素の一覧である。
その次の行(7行目)で、<h4> (タイトル)中に含まれるすべての <a> (ハイパーリンクを表す)を選択する。ここでは着目する要素は1つだけ(1行あたり1タイトル)なので、 セレクタで得られたリストのうち、先頭だけを+.pop()+ 関数を使って取り出す必要がある。
DOM中の要素の中には、実際のテキスト(マークアップ言語に含まれない、コンテンツとしてのテキスト)を含むものがある。それらに対しては8行目のように [要素名].text という書式で参照できる。そして最終行の9行目のように、ScraperWiki のコンソール画面にテキストを出力することになる。スクレイパー上で Run をクリックすると小さなウィンドウが現れ、IAEAサイト中から出来事の名前が抽出、表示される。
スクレイパーの基本的な仕組みをここまで確認した。Webページをダウンロードし、DOM形式に変換し、特定の内容を選択および抽出できる。残っている課題があれば、この基本的な骨組みをベースに、ScraperWikiやPythonのドキュメントを参考にしてみよう。
-
各事故のタイトルに対応するリンクアドレスがあるだろうか?
-
CSSのクラス名を用いて、日付や場所の情報を含む小さな箱の領域を選択し、要素のテキストを抽出できるだろうか?
-
ScraperWikiは、スクレイパーの処理結果を保存できるよう小規模なデータベースを持っている。提供されているドキュメントに含まれるサンプルを参考にすると、事故のタイトル、リンク、日付を保存できる。
-
放射能事故のリストは何ページにも渡っている。歴史的な事故を得るために複数のページにわたってスクレイピングできるか?
このような抽出に取り組んでみる場合、ScraperWikiを参考にするとよい。既にあるスクレイパーに多数の有用なサンプルがある。頻繁に参考にしよう、データは刺激を与えてくれる。このように、スクレイパーを作成するにしても、まったくゼロから始める必要はない。自分の行いたい内容に近いものを選び、手元に入手し、取り組んでいる内容に当てはめてみよう。
— Friedrich Lindenberg, Open Knowledge Foundation